
Creating a sentiment analysis with Twitter messages is not really easy due to the brevity of the texts and the frequently used irony and sarcasm. With the Azure Text Analytics API this works surprisingly well anyway.
Background
In autumn 2017, a colleague and I decided, just for fun, to save and analyse Twitter posts on the most important parties in the German federal elections. For this we used Twitter's streaming API to collect the tweets and store them in a MongoDB. The result was a data set of more than 2.2 million tweets on the subject of the German political parties and the Bundestag elections.
When I took a closer look at the Azure Text Analytics API and saw that it supports sentiment analysis as well as language detection and key phrase extraction, I thought that this tweet database might be an excellent source to test the capabilities of the API.
Prerequisites
To use the Azure Text Analytics API you need an active Microsoft Azure account. To try out the API, Microsoft offers a free usage plan that allows a maximum of 5000 transactions per month. For some tests this is enough, but if you want to work seriously with the API, you have to invest a lot. The service is not really cheap. It should also be noted that German language support is still being in preview.
The following website describes how to sign up for the API and get a valid endpoint and access key. How to sign up for Text Analytics API
A Text Sentiment Analysis with Python
My idea was to write a small Python program that fetches the tweets from the Mongo database, cleans them, converts them into the required JSON format and sends them to the Azure Text Analytics API, then receives the analysis result of the API and visualizes it together with the original tweets in an Excel sheet.
Of course the following script is only a quickly hacked proof of concept and could be improved in many ways.
The following libraries are required for the script:
from pymongo import MongoClient
import re
import sys
import time
import json
import xlsxwriter
from progressbar import Bar, Percentage, ProgressBar
import requests(Using the ProgressBar is just for fun, so waiting in front of the console is not so boring.)
Now we need the information about the Azure connection data, the database connection, the number of tweets we want to select, the temporary dictionaries for the tweets and the progress bar.
# Azure connection data (Create your Cognitive Services APIs account in the Azure portal)
subscription_key = ''
sentiment_api_url = ''
# Connect to MongoDB
connection = MongoClient("mongodb://localhost")
db = connection.bundestagswahl.tweets
# Set maximum tweets
maxtweets = 5000
# Temporary dictionaries
original_tweets = {'documents' : []}
tidied_tweets = {'documents' : []}
# Use a progress bar in your shell (for larger data sets.)
pbar1 = ProgressBar(widgets=['Analyze Tweets: ', Percentage(), Bar()], maxval=maxtweets).start()
pbar2 = ProgressBar(widgets=['Write Excel File: ', Percentage(), Bar()], maxval=maxtweets).start()Since tweets often contain special characters and links, they are first cleaned with the following helper function.
def tidy_tweet(tweet):
'''
Helper function to tidy the tweet text.
The regex removes special characters and links, etc.
'''
return ' '.join(re.sub("(@[A-Za-z0-9äöüÄÖÜß]+)|([^0-9A-Za-z9äöüÄÖÜß \t])|(\w+:\/\/\S+)", " ", tweet).split())The Azure Text Analytics API expects a JSON string in the following format.
{
'documents': [{
'id': '1',
'language': 'de',
'text': 'Das ist der Twitter Text.'
}]
}The return value of the API is as follows:
{
'documents': [{
'score': 0.5101274251937866,
'id': '1'
}],
'errors': []
}The API returns a numeric score between 0 and 1. Scores close to 1 indicate positive sentiment, while scores close to 0 indicate negative sentiment.
The following function is our main function. It creates the temporary dictionaries from the cleaned tweets, passes them to the API and then receives the sentiment result, which is finally passed to the helper function that generates the Excel sheet.
def analyze_tweets():
'''
Fetch tweets from MongoDB, write dictionary for Azure Text Analytics,
send data to Azure and receive sentiment results.
'''
tweets = []
row = 1
try:
fetched_tweets = db.find().limit(maxtweets)
i = 0
for tweet in fetched_tweets:
parsed_tweet = {}
pbar1.update(i+1)
parsed_tweet['text'] = tweet['text']
try:
if tweet['originalTweet']['retweeted_status']['retweet_count'] > 0:
if parsed_tweet['text'] not in tweets:
new_original_item = {"id": str(row), "language": "de", "text": tweet['text']}
original_tweets['documents'].append(new_original_item)
new_tidied_item = {"id": str(row), "language": "de", "text": tidy_tweet(tweet['text'])}
tidied_tweets['documents'].append(new_tidied_item)
row += 1
else:
new_original_item = {"id": str(row), "language": "de", "text": tweet['text']}
original_tweets['documents'].append(new_original_item)
new_tidied_item = {"id": str(row), "language": "de", "text": tidy_tweet(tweet['text'])}
tidied_tweets['documents'].append(new_tidied_item)
row += 1
except KeyError:
pass
tweets.append(parsed_tweet['text'])
i = i + 1
connection.close()
pbar1.finish()
# Connect to Azure Text Analytics API
headers = {"Ocp-Apim-Subscription-Key": subscription_key}
response = requests.post(sentiment_api_url, headers=headers, json=tidied_tweets)
sentiments = response.json()
write_excel_result(sentiments)
return tweets
except ConnectionError:
print("Can't connect to MongoDB :-(")The (messy) helper function generates the Excel sheet and visualizes the sentiment results.
def write_excel_result(sentiments):
'''
Helper function to write the Excel file and
visualize a simple sentiment result.
'''
workbook = xlsxwriter.Workbook('Azure_Sentiment_Analysis.xlsx')
worksheet = workbook.add_worksheet('Sentiment Analysis')
ws_row = 0
ws_col = 0
cell_format = workbook.add_format({'bg_color': '#ffffff', 'font_color': '#000000', 'border': True, 'border_color': 'silver', 'bold': True})
worksheet.write(ws_row, ws_col, "Tweet Text", cell_format)
worksheet.write(ws_row, ws_col + 1, "Azure Sentiment Value", cell_format)
worksheet.write(ws_row, ws_col + 2, "Sentiment Analysis", cell_format)
ws_row = 1
i = 0
for document in original_tweets['documents']:
pbar2.update(i+1)
for result in sentiments['documents']:
if document['id'] == result['id']:
worksheet.write(ws_row, ws_col, document['text'].replace('\n', ' ').replace('\r', ''))
worksheet.write(ws_row, ws_col + 1, str(result['score']))
if 0.5 > result['score'] >= 0.25:
cell_format = workbook.add_format({'bg_color': '#fec8d0', 'font_color': '#ba001a', 'border': True, 'border_color': 'silver'})
worksheet.write(ws_row, ws_col + 2, "Somewhat negative", cell_format)
elif 0.25 > result['score'] >= 0:
cell_format = workbook.add_format({'bg_color': '#fa9fac', 'font_color': '#ba001a', 'border': True, 'border_color': 'silver'})
worksheet.write(ws_row, ws_col + 2, "Negative", cell_format)
elif 1 >= result['score'] >= 0.75:
cell_format = workbook.add_format({'bg_color': '#93f882', 'font_color': '#066e15', 'border': True, 'border_color': 'silver'})
worksheet.write(ws_row, ws_col + 2, "Positive", cell_format)
elif 0.75 > result['score'] > 0.5:
cell_format = workbook.add_format({'bg_color': '#d9fcd2', 'font_color': '#066e15', 'border': True, 'border_color': 'silver'})
worksheet.write(ws_row, ws_col + 2, "Somewhat positive", cell_format)
elif result['score'] == 0.5:
cell_format = workbook.add_format({'bg_color': 'white', 'font_color': 'black', 'border': True, 'border_color': 'silver'})
worksheet.write(ws_row, ws_col + 2, "Neutral", cell_format)
ws_row += 1
workbook.close()
pbar2.finish()The Result
When we run the Python script the following Excel Sheet will be generated.
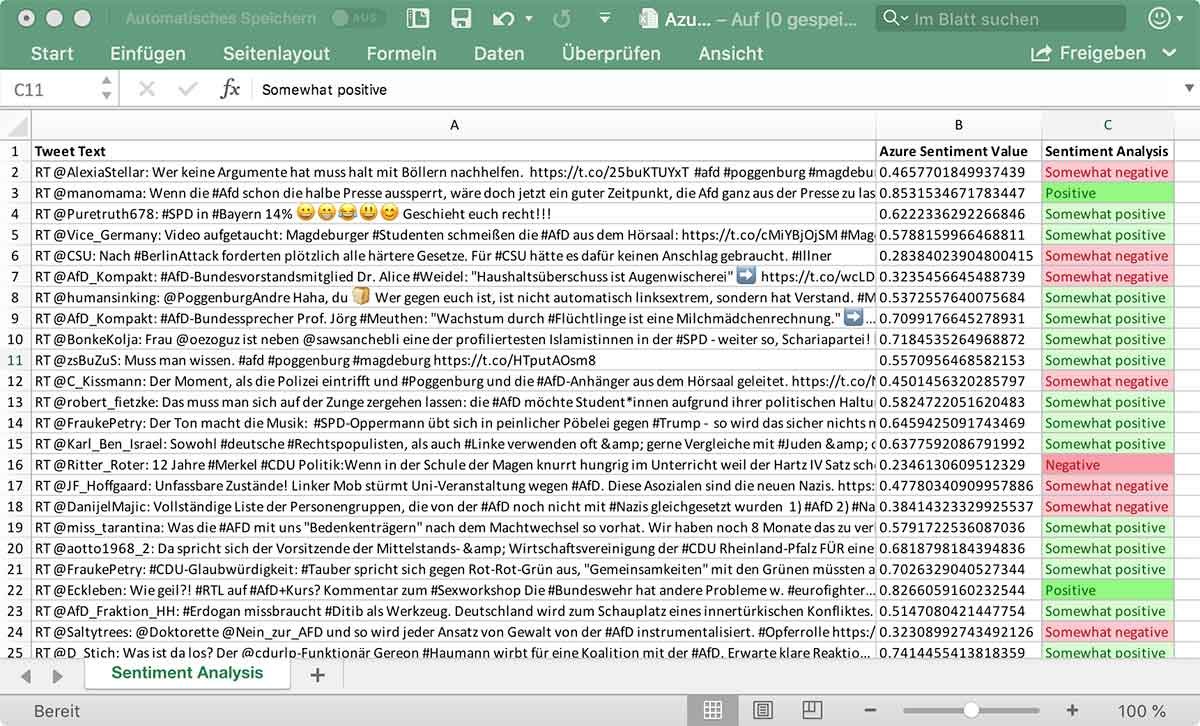
The result shows that a sentiment analysis with tweets is not yet really satisfactory. This is due to the language used (German is only available as preview) and the tweets themselves. As mentioned at the beginning, many tweets use sarcasm and irony This is hardly identifiable for the API at this time and results in false sentiment results.
Nevertheless, I find the result and the processing time of the Azure Text Analytics API impressive. If my free transaction quota hadn't been consumed so quickly, I would certainly have experimented even more with it.
You can find the whole script on my GitHub repository:
https://github.com/phookycom/twitter-sentiment-azure-xlsx
Cover image by Abby Kihano | bright-celebration-crowd-dark-431722 | CC0 License