
If you want to analyze data on current topics and opinions, Twitter is often a very good data source. To save tweets from the Twitter Streaming API to a mongoDB database easily, I wrote this little Python script.
Background
From my point of view Twitter is a good source if you want to analyze topics of current affairs, such as political changes or trends in all possible topics. The Twitter Streaming API is very well suited to capture the latest opinions and news.
With Tweepy, Python offers a powerful library to work with the Twitter API without writing too much code. And mongoDB is ideal for saving tweets and processing them later. Therefore I wrote a simple console script to filter the Twitter Streaming API with search words or Twitter hashtags and the used language and save the tweets automatically into an individual mongoDB collection.
Prerequisites
To work with the Twitter Streaming API, you first need the required API keys. More specifically, you need your personal consumer key, consumer secret, access token and access token secret. You can generate them on the following website:
Twitter Application Management
If you need a detailed description of how to create the corresponding keys, you can find nice instructions on the following website:
How to Register a Twitter App in 8 Easy Steps
The following Python packages are also required:
import tweepy
import json
from pymongo import MongoClient
import argparse
import configparserA script with parameters
I wanted a script that is as variable as possible, in which the values for search words, language, database and collection are not hard-coded, but can be passed with arguments in the console. Argparse is a parser for command-line options and arguments which makes this possible. In the code below, I defined the arguments for for the script including the help texts. With the "append" action it is possible to use more than one argument type.
We also define the mongoDB host. In my case, no access data is required.
parser = argparse.ArgumentParser()
parser.add_argument('-d','--database', help='<Required> Name of MongoDB Database (i.e. -d twitterdb)', required=True)
parser.add_argument('-c','--collection', help='<Required> Name of MongoDB collection (i.e. -c pythontweets)', required=True)
parser.add_argument('-w','--words', action='append', help='<Required> Keywords or hastags to filter the Twitter stream (i.e. -w#python)', required=True)
parser.add_argument('-l','--language', action='append', help='Language of tweets (i.e. -l en)', required=True)
args = parser.parse_args()
DATABASE = args.database
COLLECTION = args.collection
WORDS = args.words
LANGUAGES = args.language
MONGO_HOST= 'mongodb://localhost'Using the script with the help attribute (-h) generates the following output.
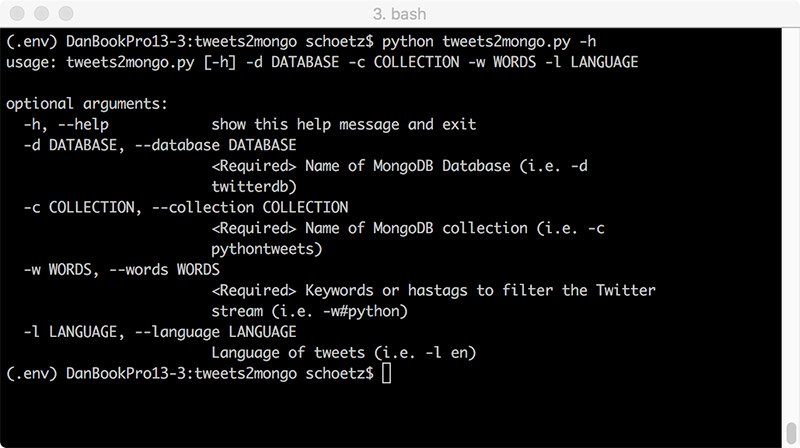
Storing the Twitter API Keys in a separate conf file.
Storing access data directly in the script is not a good idea. I used the configparser library to access the Twitter API keys stored in a separate "keys.conf" file.
KEYS_LOCATION = 'keys.conf'
def read_conf(settings_location):
#Read the Twitter API keys from the keys file.
settings = configparser.ConfigParser()
settings.optionxform = str
settings.read(settings_location)
return settings
keys = read_conf(KEYS_LOCATION)['MAIN']
auth = tweepy.OAuthHandler(keys['CONSUMER_KEY'], keys['CONSUMER_SECRET'])
auth.set_access_token(keys['ACCESS_TOKEN'], keys['ACCESS_TOKEN_SECRET'])The Twitter Listener
Ok, let's access the Twitter Streaming API with the following class and store the tweets in a mongoDB collection with the help of Tweepy's StreamListener.
We need a function called to connect to the Twitter Streaming API and function that displays an error or statuscode. The on_data function connects to the the defined mongoDB () and stores the tweets as JSON data. To monitor this, we also have the text of the respective tweet displayed in the console.
class TwitterStream(tweepy.StreamListener):
def on_connect(self):
# Function called to connect to the Twitter Streaming API
print("You are now connected to the Twitter streaming API.")
def on_error(self, status_code):
# Function displays the error or status code
print('An Error has occured: ' + repr(status_code))
return False
def on_data(self, data):
#Function connects to the defined MongoDB and stores the filtered tweets
try:
#Connect to MongoDB host
client = MongoClient(MONGO_HOST)
#Use defined database (here: tweets)
db = client[DATABASE]
# Decode the JSON data from Twitter
datajson = json.loads(data)
#Pick the 'text' data from the Tweet
tweet_message = datajson['text']
#Show the text from the tweet we have collected
print(tweet_message)
#Store the Tweet data in the defined MongoDB collection
db[COLLECTION].insert(datajson)
except Exception as e:
print(e)Finally the Twitter listener has to be initialized.
listener = TwitterStream(api=tweepy.API(wait_on_rate_limit=True))
streamer = tweepy.Stream(auth=auth, listener=listener)
print("MongoDB database: " + str(DATABASE))
print("Database collection: " + str(COLLECTION))
print("Language: " + str(LANGUAGES))
print("Keywords: " + str(WORDS))
streamer.filter(track=WORDS, languages=LANGUAGES)The script can be executed with the following example parameters:
$ python tweets2mongo.py -w#python -w#azure -w#aws -d development -c cloudcomputing -l en
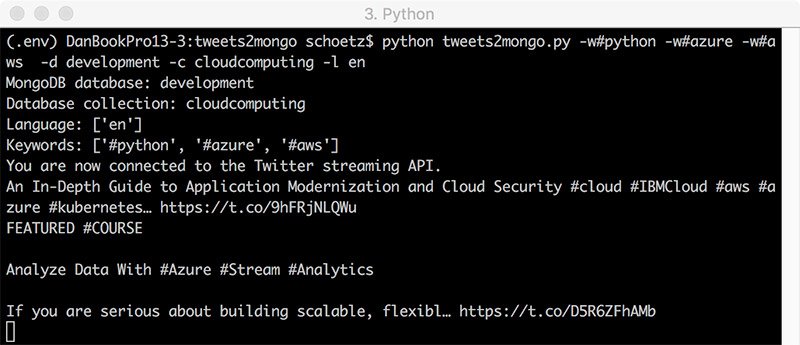
You can find the whole script on my GitHub repository:
https://github.com/phookycom/tweets2mongo
Cover image by Stable Diffusion.